
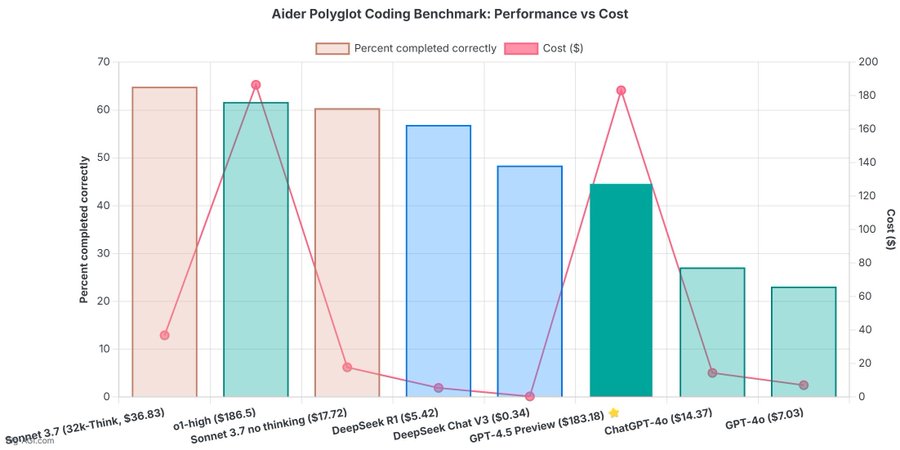
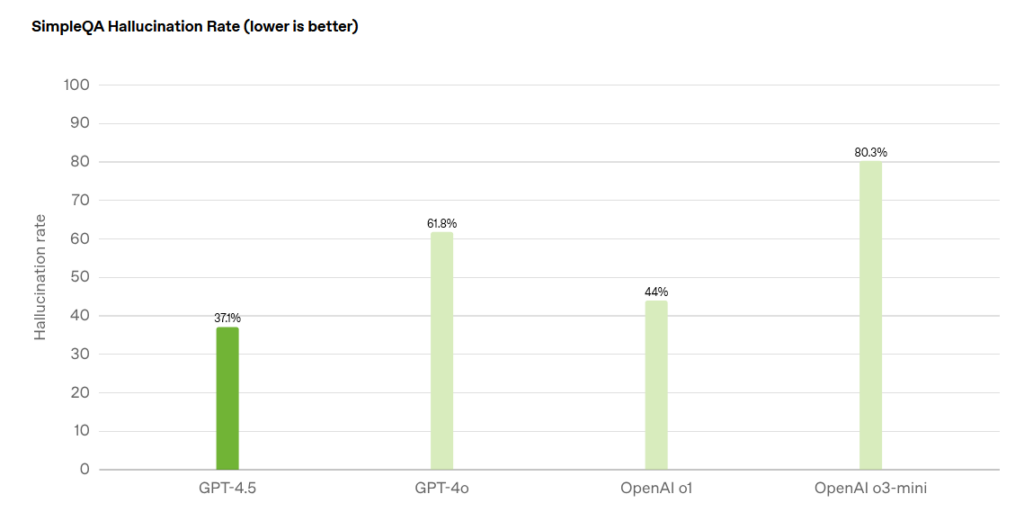
The verdict is in: OpenAI's newest and most capable traditional AI model, GPT-4.5, is big, expensive, and slow, providing marginally better performance than GPT-4o at 30x the cost for input and 15x the cost for output. The new model seems to prove that longstanding rumors of diminishing returns in training unsupervised-learning LLMs were correct and that the so-called "scaling laws" cited by many for years have possibly met their natural end.
An AI expert who requested anonymity told Ars Technica, "GPT-4.5 is a lemon!" when comparing its reported performance to its dramatically increased price, while frequent OpenAI critic Gary Marcus called the release a "nothing burger" in a blog post (though to be fair, Marcus also seems to think most of what OpenAI does is overrated).
Former OpenAI researcher Andrej Karpathy wrote on X that GPT-4.5 is better than GPT-4o but in ways that are subtle and difficult to express. "Everything is a little bit better and it's awesome," he wrote, "but also not exactly in ways that are trivial to point to."
OpenAI is well aware of these limitations, and it took steps to soften the potential letdown by framing the launch as a relatively low-key "Research Preview" for ChatGPT Pro users and spelling out the model's limitations in a GPT-4.5 release post published Thursday.
"GPT‑4.5 is a very large and compute-intensive model, making it more expensive than and not a replacement for GPT‑4o," the company wrote. "Because of this, we’re evaluating whether to continue serving it in the API long-term as we balance supporting current capabilities with building future models."
According to OpenAI's own benchmark results, GPT-4.5 scored significantly lower than OpenAI's simulated reasoning models (o1 and o3) on tests like AIME math competitions and GPQA science assessments, with GPT-4.5 scoring just 36.7 percent on AIME compared to o3-mini's 87.3 percent. Additionally, GPT-4.5 costs five times more than o1 and over 68 times more than o3-mini for input processing.

 Loading comments...
Loading comments...
